A defense of in-database AI agents: data gravity, security, transactional isolation, backups, replication, and why pg-synapse lives inside Postgres on purpose.
A working tutorial: install pg-synapse, write a tool, register an LLM profile, create an agent as a row, run it from SQL, attach a reactive trigger. All copy-pasteable.
pg-synapse is a Postgres-native agent loop runtime in Rust. Invoke LLM agents from SQL, with tools that read and write your database under the caller’s grants.
We added semantic search to agent memory, then benchmarked it against plain document RAG on the same questions. The boring baseline won by 6x. Here is why that is the point.
“Add memory to the agent” sounds like one feature. It is six different jobs that need three different mechanisms. Here is the map, with a concrete example for each.
The practical follow-up to the goldfish-memory post. Bring a Postgres database with pgvector and an agent that talks to users; an hour later you’ve got two-tier memory bolted on. Staging, realtime and consolidate cells, three scheduling options, three reader patterns, and an LLM fact extractor — Python and Rust both.
Agent memory has two completely different jobs — fast context for the next reply, and curated truth three weeks later — and most people try to do both with one tool. Here’s the two-tier pattern I built chunkshop’s memory layer around, the late-event bug that silently eats conversations, and why ‘just use pgvector’ isn’t the whole answer.
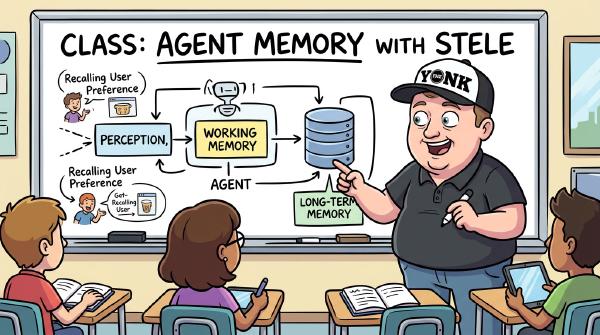
The hands-on follow-up to the why-I-built-it post. Real commands, real outputs: install Stele, wire it into your agent, store artifacts with citations, supersede facts, time-travel with as_of, stash oversized tool output, and run recall through two strategies. Five minutes to install, the rest is just typing.
I said the implementation needed another quarter. Three weeks later I’d shipped Stele — source-backed, time-traveling, sovereign agent memory that plugs into seven coding assistants. What it does, the three goals driving it, what’s solid on main, and what’s still wobbly. The honest version, including the parts that aren’t built yet.
The features I’d argue are genuinely novel — framers, hierarchical summaries, BYO embedders via four lines of YAML, schema-flex append mode, cross-language vector compatibility, and the modular-backends roadmap toward MariaDB and ClickHouse. Plus the four bets chunkshop is making about where RAG infrastructure goes next.