Long-running agents are usually given a memory system that stores facts and retrieves them by similarity, borrowed straight from RAG. We argue that’s the wrong default: cheaply re-derivable facts are net-negative to cache, while the expensive, non-re-derivable thing an agent accumulates, process, is exactly what the field under-builds. We present the Agentic Context and Protocol Ledger, validate it with two policy simulations and a four-model adversarial review, and report four empirical results on staleness, dependency-checked reuse, and the mechanisms that make imperfect dependency declaration safe.
A defense of in-database AI agents: data gravity, security, transactional isolation, backups, replication, and why pg-synapse lives inside Postgres on purpose.
A working tutorial: install pg-synapse, write a tool, register an LLM profile, create an agent as a row, run it from SQL, attach a reactive trigger. All copy-pasteable.
pg-synapse is a Postgres-native agent loop runtime in Rust. Invoke LLM agents from SQL, with tools that read and write your database under the caller’s grants.
Postgres-native agent-loop runtime in Rust. Invoke an LLM agent and its tool dispatch from SQL like a stored procedure — the agent reads and writes your tables directly, with a small trait-based kernel and everything else as a plugin.
Portable CLI for judging RAG and LLM benchmark runs across local, OpenAI-compatible, and cloud providers — a deterministic quick mode, a paraphrase-tolerant LLM-as-judge mode, and a full per-case audit trail for every verdict.
Multi-model LLM debate and second-opinion validation. Broadcasts a prompt to several models — HTTP providers or local CLIs — has them argue over N rounds, and returns a synthesized answer plus an agreement/disagreement report.
Vibe coding is a real and useful phase — the problem is people stop there. The space between ‘I had an idea on a plane’ and ’this runs in an air-gapped Kubernetes cluster’ is where the actual work happens. A generalizable playbook for the middle, starting with: treat the LLM like a very literal child.
Agents got good, code became the cheapest thing in the room, and the gap between product and engineering is closing fast. The people who internalize that — who spend their time deciding what should exist and ripping into what the agents hand back — are going to run circles around everyone else.
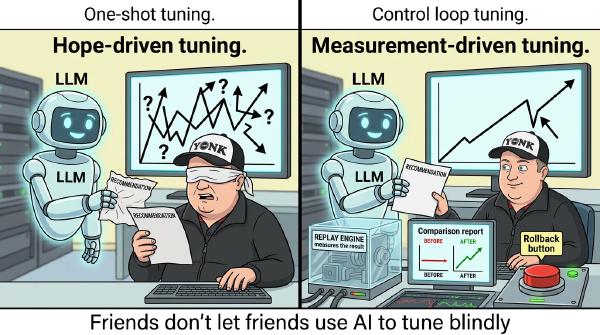
A full LLM-driven tuning loop with four real outcomes: a successful apply, an automatic rollback on regression, a safety-layer rejection, and a hint-driven redirect. No recommendations without measurement.