The Rust performance line for pg-raggraph: a real pgrx extension with async background-worker ingest and hybrid retrieval, plus a sidecar mode for managed Postgres where you can’t load an extension at all.
Apache AGE + pgvector in one PostgreSQL instance, side by side. Ask a question, watch vector-only, graph-only, and graph+vector retrieval run in parallel with timing for each.
Modern AI agents need three different kinds of memory and only one of them is RAG. The episodic, relational, time-anchored kind needs a graph — and pg-raggraph happens to be shaped exactly right. Tier 1 evolution awareness, retraction-aware retrieval, namespace isolation. What’s built, what’s still gap.
AGE is a property-graph engine; pg-raggraph is read-mostly retrieval that combines vector + BM25 + shallow graph traversal in one query plan. Where each wins, where neither fits, and the deployment story that closes off most of the postgres install base.
GraphRAG that runs entirely in PostgreSQL — pgvector for vectors, recursive CTEs for graph traversal, tsvector BM25 for keyword search. No graph database, no second backup strategy, no data sync.
Most teams reach for Neo4j or Apache AGE the moment they read the Microsoft GraphRAG paper. The honest answer is most GraphRAG workloads don’t need a graph database — pgvector + recursive CTEs + tsvector handle 1-3 hop traversal in one ACID database.
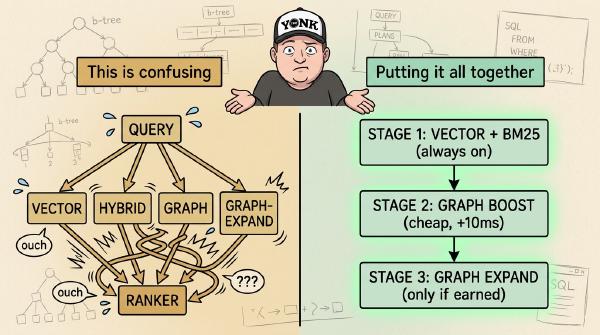
Part 3 of 3. 391 real SCOTUS cases, four retrieval strategies running side by side, multi-hop Cypher that no hybrid search can match, and the production-ready 3-stage architecture you should actually ship.
Part 2 of 3. A complete Docker setup for Postgres 16 with pgvector and Apache AGE, plus your first vector similarity query and your first Cypher traversal — with the gotchas that cost me an afternoon the first time.
Part 1 of 3. Users ask three shapes of questions and only one of them needs a graph. Honest benchmarks, a 3-stage retrieval architecture, and why graph is a multiplier — not a replacement.
Runnable sample app: Postgres 16 with Apache AGE and pgvector, a FastAPI orchestrator, and four retrieval strategies compared side by side on 391 real SCOTUS cases.