A 150-row benchmark grid looks like the output of a robot having a stroke — until you know the three things each row tells you. A field guide to reading our RAG bake-off: read the parametric floor first, decode the system and lane columns, and ask the only two questions that matter — is it right, and what did it cost?
One failing LoCoMo question turned into a cross-corpus, multi-system benchmark — and a pile of retracted conclusions. Small-N runs lie, cross-vendor numbers are rarely apples-to-apples, and a correctness bug will impersonate an architecture win every time. Run the no-context baseline, 6x your sample, and diff the bytes that reach the model before you trust any RAG number.
Strip the filler words out of your documents before you embed them and embedding gets ~25% cheaper for one to two points of retrieval accuracy — flat, across every model I tried. The real lesson isn’t the caveman trick: it’s that twelve test questions will lie to you with a perfectly straight face, and a clean model-by-model story can be complete garbage until you run a few hundred.
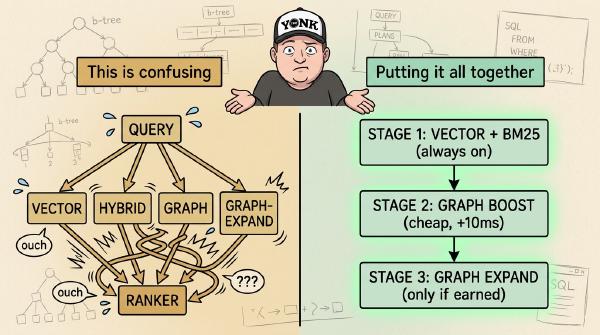
Part 3 of 3. 391 real SCOTUS cases, four retrieval strategies running side by side, multi-hop Cypher that no hybrid search can match, and the production-ready 3-stage architecture you should actually ship.