Vibe coding is a real and useful phase — the problem is people stop there. The space between ‘I had an idea on a plane’ and ’this runs in an air-gapped Kubernetes cluster’ is where the actual work happens. A generalizable playbook for the middle, starting with: treat the LLM like a very literal child.
Agentic memory implemented natively in PostgreSQL — the episodic, relational, time-anchored memory layer agents actually forget, kept in the database you already run.
Agents got good, code became the cheapest thing in the room, and the gap between product and engineering is closing fast. The people who internalize that — who spend their time deciding what should exist and ripping into what the agents hand back — are going to run circles around everyone else.
Modern AI agents need three different kinds of memory and only one of them is RAG. The episodic, relational, time-anchored kind needs a graph — and pg-raggraph happens to be shaped exactly right. Tier 1 evolution awareness, retraction-aware retrieval, namespace isolation. What’s built, what’s still gap.
AGE is a property-graph engine; pg-raggraph is read-mostly retrieval that combines vector + BM25 + shallow graph traversal in one query plan. Where each wins, where neither fits, and the deployment story that closes off most of the postgres install base.
GraphRAG that runs entirely in PostgreSQL — pgvector for vectors, recursive CTEs for graph traversal, tsvector BM25 for keyword search. No graph database, no second backup strategy, no data sync.
Most teams reach for Neo4j or Apache AGE the moment they read the Microsoft GraphRAG paper. The honest answer is most GraphRAG workloads don’t need a graph database — pgvector + recursive CTEs + tsvector handle 1-3 hop traversal in one ACID database.
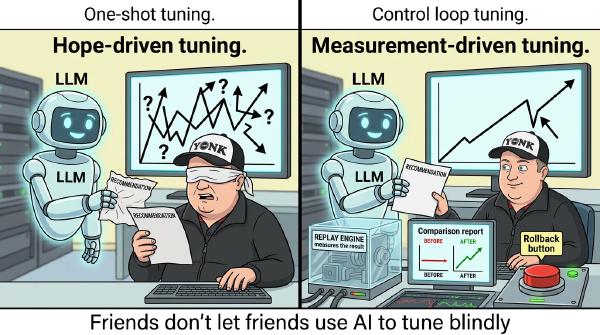
A full LLM-driven tuning loop with four real outcomes: a successful apply, an automatic rollback on regression, a safety-layer rejection, and a hint-driven redirect. No recommendations without measurement.
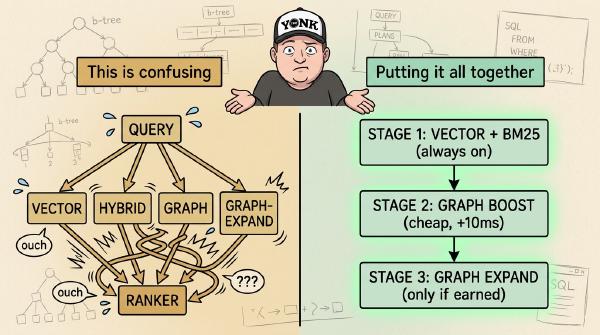
Part 3 of 3. 391 real SCOTUS cases, four retrieval strategies running side by side, multi-hop Cypher that no hybrid search can match, and the production-ready 3-stage architecture you should actually ship.
Part 1 of 3. Users ask three shapes of questions and only one of them needs a graph. Honest benchmarks, a 3-stage retrieval architecture, and why graph is a multiplier — not a replacement.