A 150-row benchmark grid looks like the output of a robot having a stroke — until you know the three things each row tells you. A field guide to reading our RAG bake-off: read the parametric floor first, decode the system and lane columns, and ask the only two questions that matter — is it right, and what did it cost?
One failing LoCoMo question turned into a cross-corpus, multi-system benchmark — and a pile of retracted conclusions. Small-N runs lie, cross-vendor numbers are rarely apples-to-apples, and a correctness bug will impersonate an architecture win every time. Run the no-context baseline, 6x your sample, and diff the bytes that reach the model before you trust any RAG number.
Strip the filler words out of your documents before you embed them and embedding gets ~25% cheaper for one to two points of retrieval accuracy — flat, across every model I tried. The real lesson isn’t the caveman trick: it’s that twelve test questions will lie to you with a perfectly straight face, and a clean model-by-model story can be complete garbage until you run a few hundred.
The practical follow-up to the goldfish-memory post. Bring a Postgres database with pgvector and an agent that talks to users; an hour later you’ve got two-tier memory bolted on. Staging, realtime and consolidate cells, three scheduling options, three reader patterns, and an LLM fact extractor — Python and Rust both.
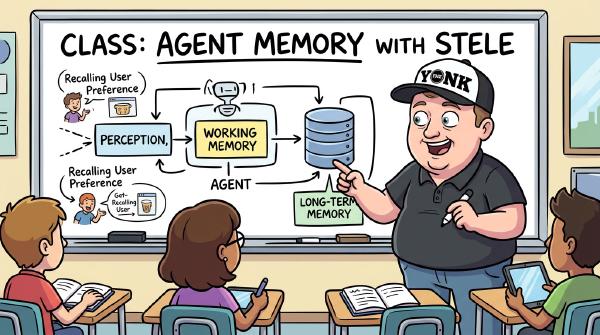
Agent memory has two completely different jobs — fast context for the next reply, and curated truth three weeks later — and most people try to do both with one tool. Here’s the two-tier pattern I built chunkshop’s memory layer around, the late-event bug that silently eats conversations, and why ‘just use pgvector’ isn’t the whole answer.
The hands-on follow-up to the why-I-built-it post. Real commands, real outputs: install Stele, wire it into your agent, store artifacts with citations, supersede facts, time-travel with as_of, stash oversized tool output, and run recall through two strategies. Five minutes to install, the rest is just typing.
Companies are quietly pulling back on open source out of fear of AI-powered cloners. They’re about to discover they unplugged themselves from the only distribution channel that matters next. Training data presence is the new SEO, and closed source just opted out.
I said the implementation needed another quarter. Three weeks later I’d shipped Stele — source-backed, time-traveling, sovereign agent memory that plugs into seven coding assistants. What it does, the three goals driving it, what’s solid on main, and what’s still wobbly. The honest version, including the parts that aren’t built yet.
Karpathy posts a thought, and six weeks later the right way to do it has been decided by whoever shipped the cleanest demo. The innovation cycle compressed from years to weeks — and that changes the shape of every competitive question. You don’t need to be first. You need to be in the window.
Every project I’ve shipped in the last six months has been an ugly baby at some point — dead code, 11pm ideas that look stupid at 8am, three abstractions doing the same thing. That’s not failure, it’s the artifact you need. Put the ugly baby in a glass case, learn from it, then rebuild from zero.