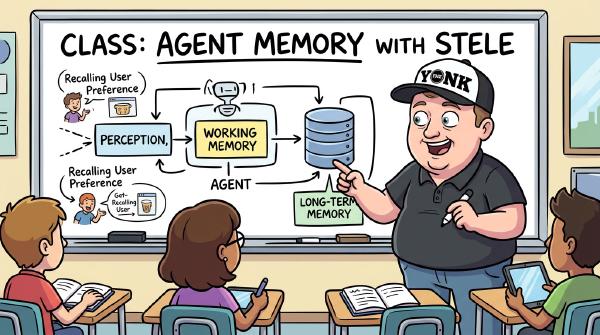
Agent memory has two completely different jobs — fast context for the next reply, and curated truth three weeks later — and most people try to do both with one tool. Here’s the two-tier pattern I built chunkshop’s memory layer around, the late-event bug that silently eats conversations, and why ‘just use pgvector’ isn’t the whole answer.
The hands-on follow-up to the why-I-built-it post. Real commands, real outputs: install Stele, wire it into your agent, store artifacts with citations, supersede facts, time-travel with as_of, stash oversized tool output, and run recall through two strategies. Five minutes to install, the rest is just typing.
Companies are quietly pulling back on open source out of fear of AI-powered cloners. They’re about to discover they unplugged themselves from the only distribution channel that matters next. Training data presence is the new SEO, and closed source just opted out.
I said the implementation needed another quarter. Three weeks later I’d shipped Stele — source-backed, time-traveling, sovereign agent memory that plugs into seven coding assistants. What it does, the three goals driving it, what’s solid on main, and what’s still wobbly. The honest version, including the parts that aren’t built yet.
Karpathy posts a thought, and six weeks later the right way to do it has been decided by whoever shipped the cleanest demo. The innovation cycle compressed from years to weeks — and that changes the shape of every competitive question. You don’t need to be first. You need to be in the window.
Every project I’ve shipped in the last six months has been an ugly baby at some point — dead code, 11pm ideas that look stupid at 8am, three abstractions doing the same thing. That’s not failure, it’s the artifact you need. Put the ugly baby in a glass case, learn from it, then rebuild from zero.
Vibe coding is a real and useful phase — the problem is people stop there. The space between ‘I had an idea on a plane’ and ’this runs in an air-gapped Kubernetes cluster’ is where the actual work happens. A generalizable playbook for the middle, starting with: treat the LLM like a very literal child.
Agents got good, code became the cheapest thing in the room, and the gap between product and engineering is closing fast. The people who internalize that — who spend their time deciding what should exist and ripping into what the agents hand back — are going to run circles around everyone else.
The features I’d argue are genuinely novel — framers, hierarchical summaries, BYO embedders via four lines of YAML, schema-flex append mode, cross-language vector compatibility, and the modular-backends roadmap toward MariaDB and ClickHouse. Plus the four bets chunkshop is making about where RAG infrastructure goes next.
Modern AI agents need three different kinds of memory and only one of them is RAG. The episodic, relational, time-anchored kind needs a graph — and pg-raggraph happens to be shaped exactly right. Tier 1 evolution awareness, retraction-aware retrieval, namespace isolation. What’s built, what’s still gap.